Timeseries Data at BIT
Timeseries Data at BIT
We’ve all been tempted at some point to “quickly” install a new thing to test it out, and before you know it, it’s suddenly running in production—because, as the saying goes, ‘nothing is as permanent as a temporary solution’.
This approach doesn’t typically lead to reliable service delivery, so when time-series data became business-critical (not least because it was being used for billing), it was time for a structural solution.
What is Timeseries Data?
Time-series data is, in principle, telemetry generated at regular (or irregular) intervals. It reflects the state of something at a given moment. Examples include memory or CPU usage, the number of web requests processed, temperature measurements, or even when doors open.
This data can produce interesting graphs, as seen, for example, by our customers in the BIT Portal. We can observe things like a disk filling up, the busiest times of day or week for traffic, or even debug an issue by looking for notable patterns in the data—such as realising that it’s not a web server that’s overloaded, but a database.
The Challenge
Initially, we had one large, standalone InfluxDB containing both business-critical data and old test data. Redundancy was later added to this system by snapshotting and copying the filesystem every 5 minutes, but this was a one-way solution—and not the most elegant one.
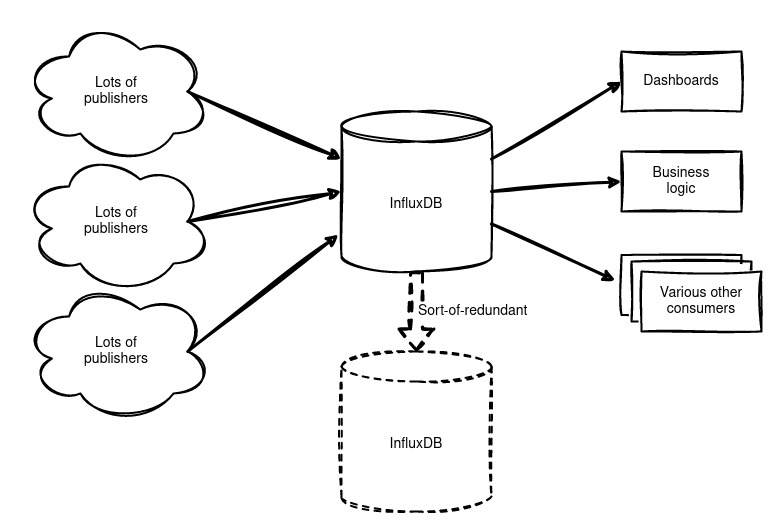
What We Wanted
All the usual things. We aimed for a solution that was redundant, highly available, scalable, flexible, and free from data loss. Additionally, we wanted the ability to migrate easily, both now and in the future, while adhering to open-source principles and local hosting—without relying on cloud solutions.
And a pony.
The Solution
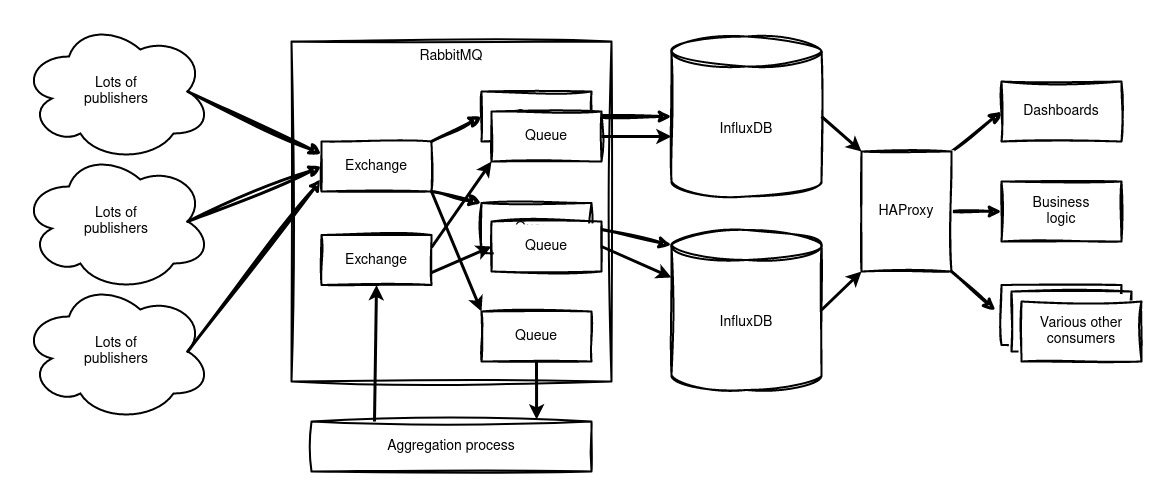
We introduced a message bus into our architecture. Data producers write to this message bus, which could be anything from Telegraf processes collecting server statistics to homemade temperature sensors. The message bus stores these messages in queues until they’re read—in our case, by a redundant pair of InfluxDB instances.
Reading from these InfluxDBs happens via a load balancer, ensuring our dashboards and business processes always have access to an available database. Certain processes can even read directly from their own queue on the message bus.
We chose RabbitMQ as our message bus.
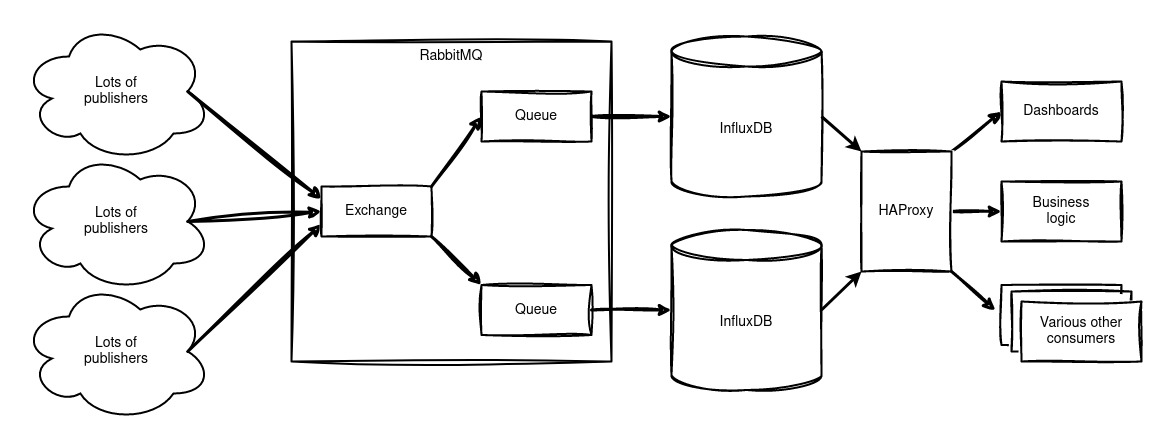
Why RabbitMQ?
While Apache Kafka is often used in high-volume applications, we opted for RabbitMQ due to its broad functionality, which aligns well with BIT’s needs.
RabbitMQ is implemented as a high-availability cluster that uses a quorum—meaning there are three servers, and a majority must agree. For example, if a network split occurs and one server becomes isolated, the remaining two will form a majority and continue operating, while the isolated one becomes a minority and stops working.
The queues follow the same principle and are stored across all three servers, so if one fails, the data remains available. In the unlikely event that the entire cluster goes offline, the queues won’t be lost because they’re stored on disk.
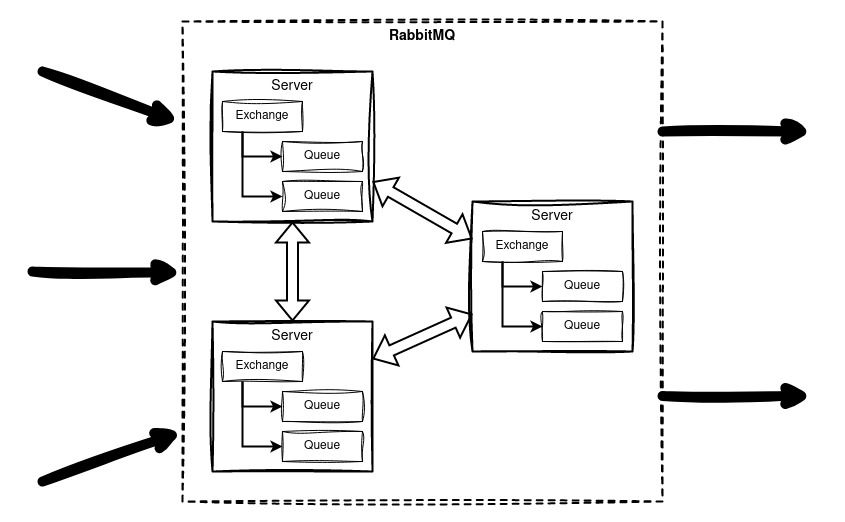
The Result
This architecture results in a high-availability InfluxDB cluster, enabling maintenance without downtime. Data is retained in queues and automatically written once a server comes back online.
It’s also possible to route the raw data stream—or parts of it, if desired—to an aggregation process for long-term storage (more on that later), to a separate database for specific data types, or to dedicated long-term storage. Additionally, data can be forwarded to a parallel database running alongside the current one, making migration much easier.
Easy Migration
Adding a message bus allows us to migrate incrementally, without needing to switch everything over at once. This makes migrating data producers and databases significantly simpler, with minimal impact on ongoing processes.
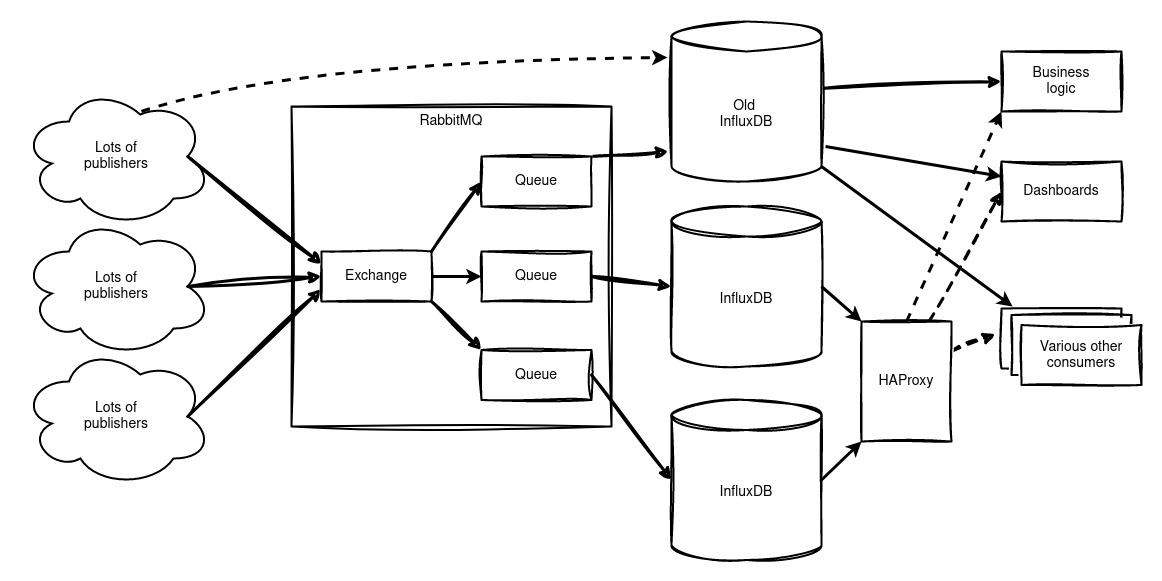
InfluxDB Versions
The original plan was to migrate from InfluxDB version 1 to version 2. However, version 2 uses the Flux language instead of InfluxQL, meaning all queries in all users and dashboards would need rewriting. Without a message bus, this would have to happen all at once, significantly increasing the risk of errors.
In late 2023, InfluxDB version 3.0 was announced. This version reverts to using InfluxQL (and standard SQL) instead of Flux, which is being phased out. As a result, we decided against migrating to version 2, but the flexibility will certainly come in handy when it’s time to move to version 3—or even to an entirely different solution.
Data Aggregation
In short, data aggregation is the process of converting high-resolution data (e.g., one data point every 10 seconds) into lower-resolution data (e.g., one data point every 5 minutes). Typically, the minimum, maximum, average, count, and sum of values are stored. This aggregated data takes up significantly less space and speeds up queries over longer periods, making it practical for long-term storage.
In InfluxDB version 1, data aggregation requires creating a Continuous Query for each type of measurement, which is both impractical and resource-intensive.
An alternative approach is using Kapacitor, which can subscribe to a database and use TICK scripts to aggregate and rewrite data. However, this process is also demanding, and Kapacitor is tied to InfluxDB version 1, making it an inflexible solution for the future.
By adding an extra queue to our message bus, we can use Telegraf to summarise the data every 5 minutes and write it back to RabbitMQ. This allows us to send the aggregated data to all database servers, resulting in a surprisingly efficient process where all databases hold identical aggregated data.
Conclusion
This setup provides both robustness and flexibility. Each component can be stopped with minimal impact, without significant downtime or the need for lengthy maintenance windows.
It’s possible to take RabbitMQ or InfluxDB servers offline for maintenance during office hours. At worst, this would result in a broken connection that should automatically reconnect, ensuring seamless operation.
The same principle applies to replacing or adding servers. Even in the extreme case of migrating from RabbitMQ to Kafka, this can be done online with minimal downtime, by installing the new cluster alongside the old one and migrating step by step, as described earlier.
While this process may involve considerable effort, there’s no need to take everything offline in the middle of the night during a maintenance window—making it a better experience for everyone.
By: The people at BIT
