
- 01-04-25BIT as a Service
- 26-03-25Internetproviders verliezen rechtszaak over blokkeren websites
- 19-02-25BIT introduceert server-side e-mailfiltering met Sieve
- 06-02-25Shared hosting wordt opgefrist
- 28-11-24ECOFED uitgeroepen tot publieksfavoriet bij Computable Awards
- 21-11-24Een goede cloud heeft een kundige dirigent nodig
- 17-10-24ECOFED wint ICT Innovatieprijs Regio Foodvalley 2024
- 01-08-24BIT geeft kaarten weg voor F1 in Zandvoort
- 24-04-24Status.bit.nl in nieuw jasje!
- 12-04-24Nieuw bij BIT: GPU hosting
Timeseries data bij BIT
14-02-2024 07:15:00
We hebben allemaal wel eens de neiging gehad om "even snel" een nieuw ding te installeren om te testen, en voor je het weet draait het ineens in productie, want zoals het gezegde gaat 'niets is zo permanent als een tijdelijke oplossing'.
Deze aanpak leidt doorgaans niet tot betrouwbare dienstverlening, dus toen de timeseries data bedrijfskritisch begon te worden, omdat deze onder andere voor facturatie werd gebruikt, werd het tijd voor een structurele oplossing.
Wat is timeseries data?
Timeseries data is, in principe, telemetrie die op reguliere (of niet) intervallen wordt gegenereerd. Het geeft de status weer van een ding op een zeker moment. Voorbeelden zijn het gebruik van geheugen of CPU, het aantal verwerkte web requests, temperatuurmetingen, of zelfs wanneer deuren open gaan.
Deze data kan interessante grafieken opleveren, zoals bijvoorbeeld te zien is voor onze klanten in de BIT Portal. We kunnen bijvoorbeeld zien dat een disk aan het vollopen is, of op welk moment van de dag of van de week het meeste verkeer wordt gedaan, of zelfs een probleem debuggen door naar opvallende patronen in de data te zoeken, en dan zie je bijvoorbeeld dat niet een webserver is overbelast, maar een database.
De uitdaging
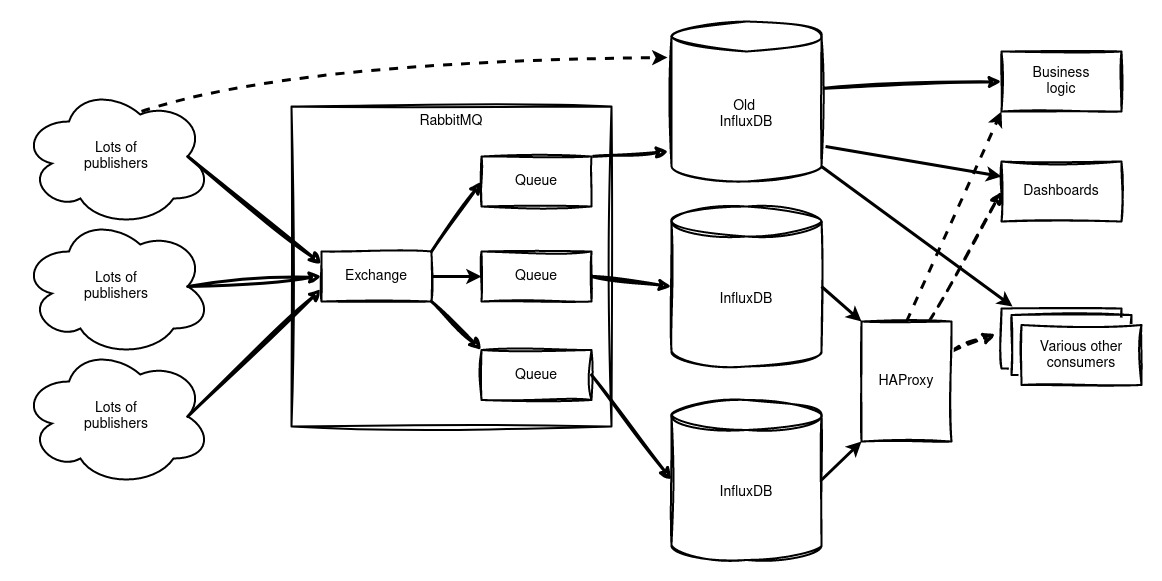
Aanvankelijk hadden we één grote, losstaande InfluxDB die zowel bedrijfskritische data als oude testdata bevatte. In dit systeem is redundantie later toegevoegd door het filesystem iedere 5 minuten te snapshotten en te kopiëren, maar dat was een eenrichtingsoplossing, en ook niet de meest elegante.
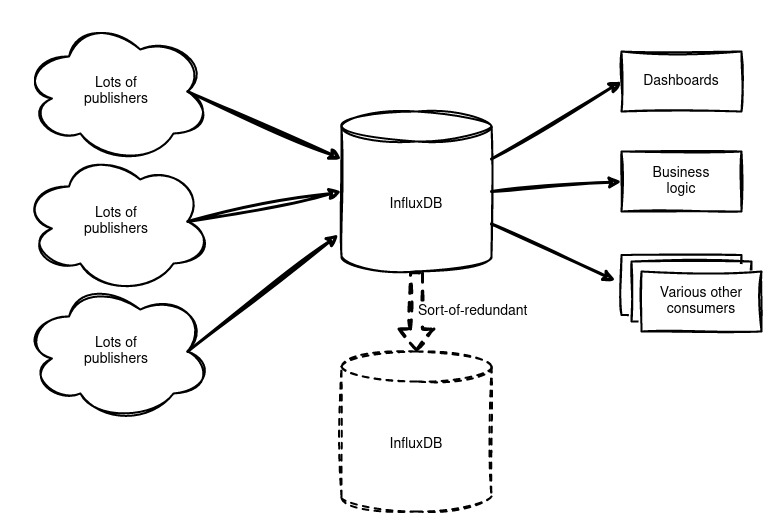
Wat wilden we
Alle gebruikelijke dingen. We streefden naar een oplossing die redundant, hoog beschikbaar, schaalbaar, flexibel en vrij van dataverlies was. Bovendien wilden we de mogelijkheid hebben om gemakkelijk te migreren, zowel nu als in de toekomst, met behoud van open-source principes en lokale hosting, zonder afhankelijk te zijn van cloudoplossingen.
En een pony.
De oplossing
We hebben een messagebus toegevoegd aan onze architectuur. Data-producenten schrijven naar deze messagebus. Dat kan van alles zijn, van Telegraf-processen die serverstatistieken verzamelen tot zelfgemaakte temperatuursensoren. De messagebus slaat deze berichten op in wachtrijen totdat ze worden gelezen, in ons geval door een redundant paar InfluxDB's.
Lezen uit deze InfluxDB's gebeurt via een load balancer, waardoor onze dashboards en bedrijfsprocessen altijd toegang hebben tot een beschikbare database. Bepaalde processen kunnen zelfs direct uit hun eigen wachtrij op de messagebus lezen.
We hebben RabbitMQ gekozen als onze messagebus.
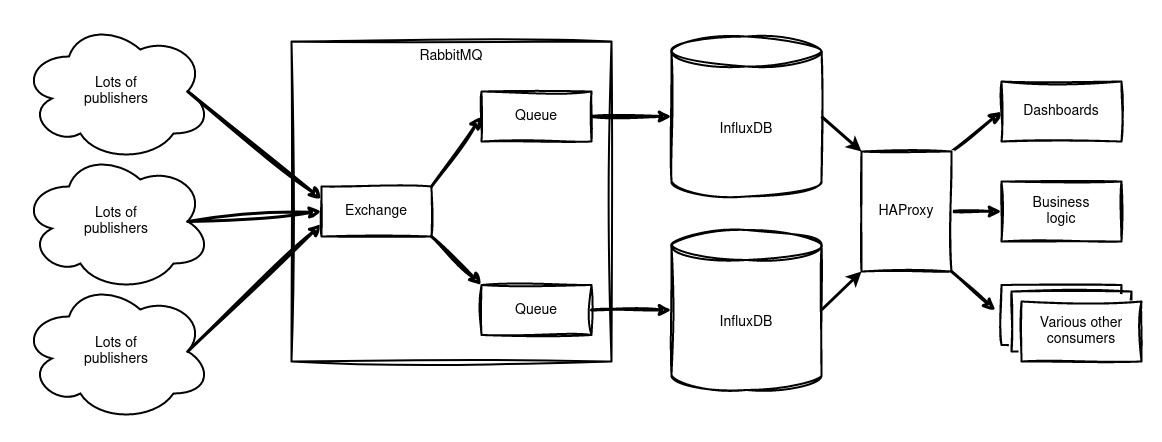
Waarom RabbitMQ?
Hoewel Apache Kafka vaak wordt gebruikt in hoog-volume toepassingen, kozen we voor RabbitMQ vanwege zijn brede functionaliteit, die goed aansluit bij de behoeften van BIT.
RabbitMQ is geïmplementeerd als een high-availability cluster dat van een quorum gebruikmaakt, dat wil zeggen dat er drie servers zijn waar de meerderheid het met elkaar eens moet zijn. Dus als er bijvoorbeeld een net-split plaatsvindt en een server geïsoleerd raakt, dan zullen de overgebleven twee een meerderheid vormen en blijven werken terwijl die ene een minderheid vormt en zal stoppen met werken.
De wachtrijen gebruiken hetzelfde principe en worden opgeslagen op alle drie de servers, dus als er één uitvalt zal de data nog steeds beschikbaar zijn. In het onwaarschijnlijke geval dat het hele cluster offline gaat zullen de wachtrijen niet verloren zijn omdat deze op disk opgeslagen worden.
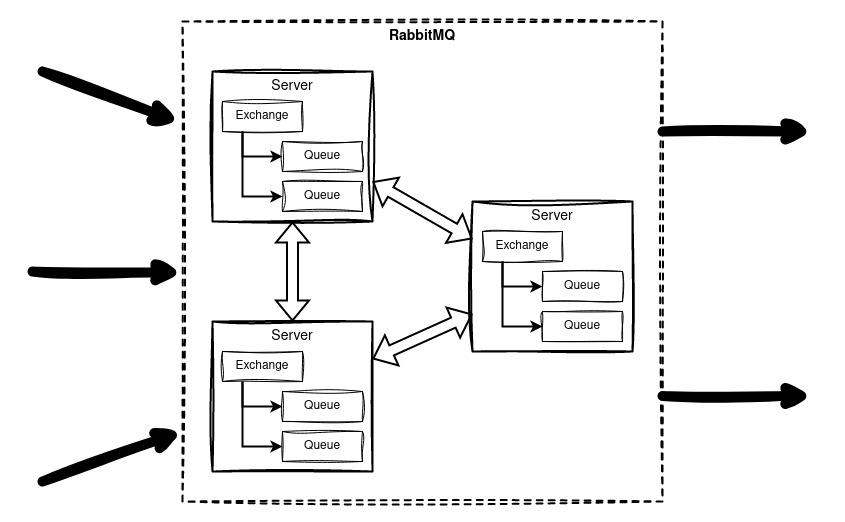
Het resultaat
Deze architectuur resulteert in een high-availability InfluxDB-cluster, dat onderhoud zonder uitval mogelijk maakt. Data wordt bewaard in wachtrijen en wordt automatisch weggeschreven zodra een server weer online is.
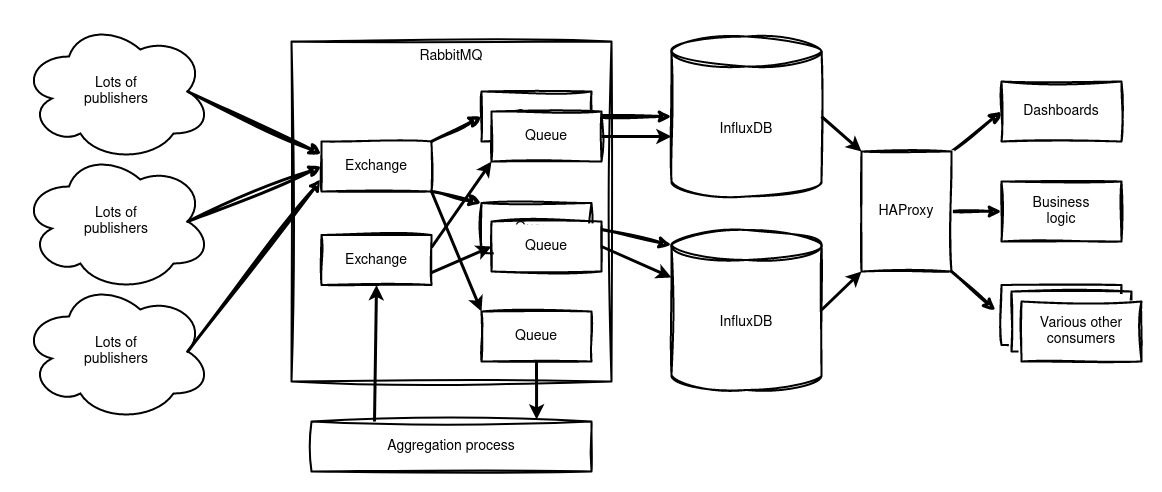
Het is ook mogelijk om de ruwe datastroom, of gedeelten daarvan indien gewenst, door te leiden naar een aggregatieproces voor langdurige gegevensopslag (zie verderop), of naar een aparte database voor specifieke datatypes, of naar aparte langetermijnopslag. Ook is het mogelijk om data door te sturen naar een parallelle database die gelijktijdig draait met de huidige, waardoor migreren veel makkelijker wordt.
Makkelijk migreren
Het toevoegen van een messagebus stelt ons in staat om stapsgewijs te migreren, zonder alles in één keer te hoeven omzetten. Dit maakt het migreren van dataproducenten en databases aanzienlijk eenvoudiger, met minimale impact op de lopende processen.
InfluxDB versies
Het oorspronkelijke plan was om de migratie van InfluxDB versie 1 naar versie 2 uit te voeren. Echter, versie 2 maakt gebruik van de Flux-taal in plaats van InfluxQL, wat betekent dat alle queries in alle gebruikers en dashboards herschreven moeten worden. Zonder een messagebus zou dit alles in één keer moeten gebeuren, wat het risico op fouten aanzienlijk vergroot.
Eind 2023 jaar werd InfluxDB versie 3.0 aangekondigd. Deze versie keert terug naar het gebruik van InfluxQL (en normaal SQL), in plaats van Flux. Flux zal worden uitgefaseerd. Hierdoor hebben we besloten af te zien van de migratie naar versie 2, maar de flexibiliteit ervan zal zeker van pas komen wanneer het tijd is om naar versie 3 over te stappen, of zelfs naar een geheel andere oplossing.
Data aggregatie
Kort samengevat is data-aggregatie een proces waarbij data van hoge resolutie (bijvoorbeeld een datapunt per 10 seconden) wordt omgezet in data van lagere resolutie (bijvoorbeeld een datapunt per 5 minuten). Vaak worden daarbij het minimum, maximum, gemiddelde, aantal datapunten en de optelling van de waardes opgeslagen. Deze geaggregeerde data neemt aanzienlijk minder ruimte in beslag en versnelt database queries over langere periodes, waardoor het praktisch is voor langere termijn data-opslag.
In InfluxDB versie 1 betekent data-aggregatie het aanmaken van een Continuous Query voor elk type meetpunt, wat zowel onpraktisch als resource-intensief is.
Een alternatieve aanpak is het gebruik van Kapacitor, dat zich kan abonneren op een database en TICK-scripts gebruikt om data te aggregeren en terug te schrijven. Dit proces is echter ook veeleisend, en Kapacitor is gebonden aan InfluxDB versie 1, waardoor het geen flexibele oplossing is voor de toekomst.
Door een extra wachtrij aan onze messagebus toe te voegen, kunnen we Telegraf gebruiken om de data elke 5 minuten samen te vatten en terug te schrijven naar RabbitMQ. Hierdoor kunnen we deze geaggregeerde data ook naar alle database servers schrijven. Dit blijkt een verrassend efficiënt proces te zijn, waardoor alle databases identieke geaggregeerde data hebben.
Conclusie
Deze opzet biedt ons zowel robuustheid als flexibiliteit. Elk onderdeel kan met minimale impact worden gestopt, zonder aanzienlijke downtime en zonder noodzaak voor uitgebreide onderhoudsvensters.
Het is mogelijk om RabbitMQ- of InfluxDB-servers tijdens kantooruren uit te schakelen voor onderhoud. Dit zou hooguit leiden tot een onderbroken verbinding, die automatisch opnieuw verbinding zou moeten maken, waardoor elk onderdeel naadloos blijft functioneren.
Ditzelfde principe geldt ook voor het vervangen of toevoegen van servers. Zelfs in het extreme geval waarin we bijvoorbeeld van RabbitMQ naar Kafka willen migreren, kan dit online worden gedaan met minimale downtime. Dit wordt bereikt door het nieuwe cluster naast het oude te installeren en alles stap voor stap te migreren, zoals eerder beschreven.
Hoewel dit proces mogelijk veel werk met zich meebrengt, is het niet nodig om midden in de nacht alles offline te halen tijdens een onderhoudsvenster, wat voor iedereen een betere ervaring oplevert.